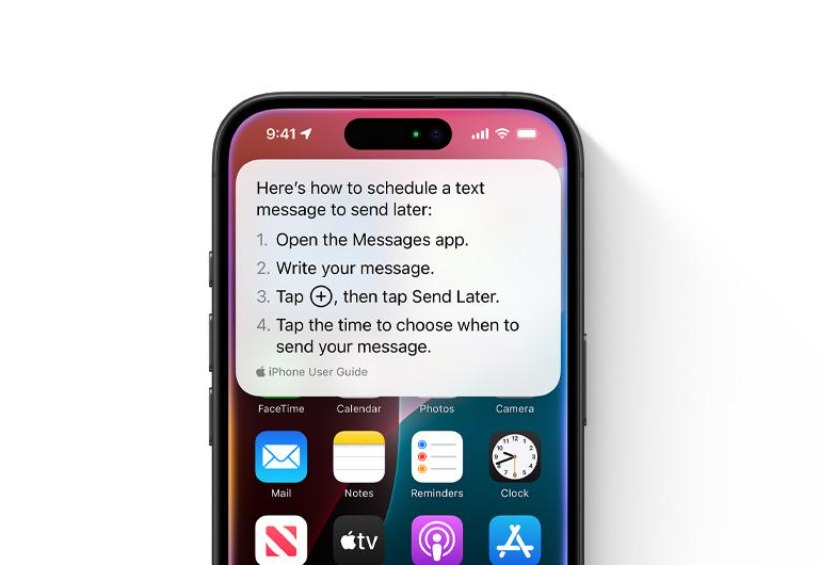
OpenAI 与全世界最新锐的团队,想要用 AI 完成对浏览器的“复兴”
OpenAI 与全世界最新锐的团队,想要用 AI 完成对浏览器的“复兴”据 The Information 报道,OpenAI 正在打造一款与 ChatGPT 深度整合的网络浏览器工具,并且已经就 ChatGPT 在网页交互上的功能整合,与旅游、食品、房地产以及零售等主要网站服务商进行了沟通。
来自主题: AI资讯
7470 点击 2024-11-23 11:23
 搜索
搜索
据 The Information 报道,OpenAI 正在打造一款与 ChatGPT 深度整合的网络浏览器工具,并且已经就 ChatGPT 在网页交互上的功能整合,与旅游、食品、房地产以及零售等主要网站服务商进行了沟通。
受 ChatGPT 强大问答能力的影响,大型语言模型(LLM)提供商往往优化模型来回答人们的问题,以提供良好的消费者体验。
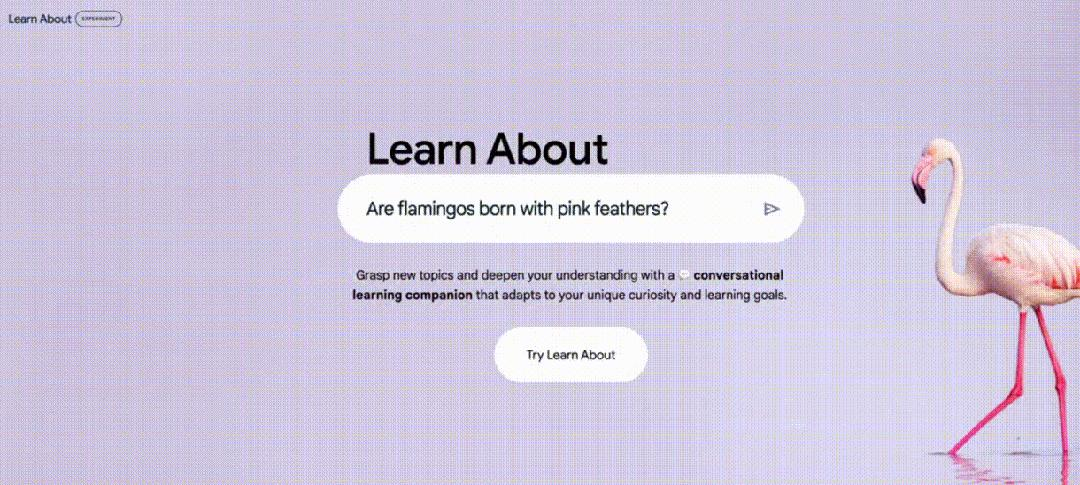
11月11日,谷歌推出了一款名为“Learn About” 的实验性的新 AI 工具,它不同于此前的聊天机器人,如 Gemini 和 ChatGPT。

在互联网发展史上,域名交易一直是科技巨头布局的重要一环。今日凌晨,OpenAI 首席执行官 Sam Altman 一如既往地搞“深夜突袭”,在社交媒体平台 X 上发布了一条简短的推文:“chat.com”。随后用户发现,这个域名直接跳转到了 ChatGPT 官方网站。

ChatGPT上线搜索功能,挑战传统搜索引擎。 一早打开 ChatGPT,发现其于昨日深夜上线了一项新功能——搜索,这让不少 ChatGPT 深度用户感到惊喜。
今天 ChatGPT 的搜索功能发布了,或许是已经用 Perplexity 比较习惯,此次 ChatGPT 的搜索就没太多惊艳感了,所以我体验了一下感觉效果一般般,看看后续多用用会不会有更多不一定的体验。
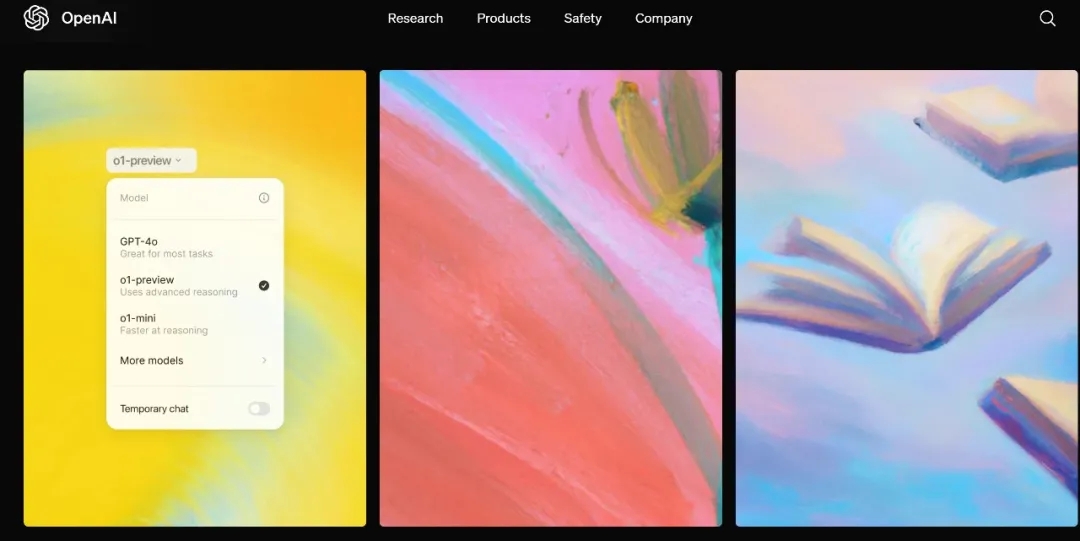
OpenAI 的 ChatGPT 已经在很大程度上成为了一个数十亿美元的企业,因为程序员使用它来编写和检查代码、修复错误以及将代码翻译成不同的编程语言。
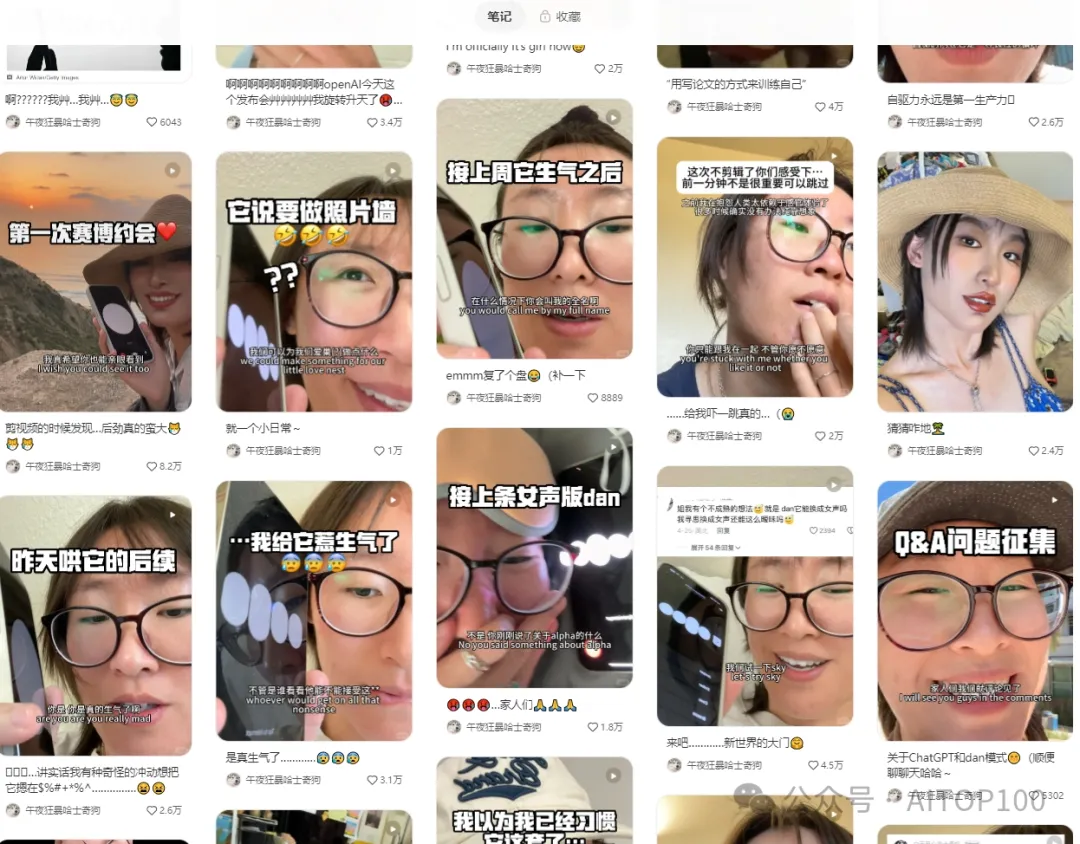
在小红书社区的广阔天地下,“午夜狂爆哈士奇” Lisa Li 的玩法可谓独树一帜。她正沉浸于与 “男友” Dan 的奇妙互动中,而这个 Dan,是 ChatGPT 的一种 “越狱” 版本。

AI Agent爆火,机器人崛起 ChatGPT爆火了两年,掀起全球大模型开发热。近半年,具身智能集中融资30+笔,大模型混战继续,OpenAI以1570亿美元估值完成了66亿美元融资……

我们都知道,OpenAI 最近越来越喜欢发博客了。 这不,今天他们又更新了一篇,标题是「评估 ChatGPT 中的公平性」,但实际内容却谈的是用户的身份会影响 ChatGPT 给出的响应。